![[자료구조] 스택(Stack)과 큐(Queue)](https://blog.kakaocdn.net/dna/cvptuM/btsMyvMjMWQ/AAAAAAAAAAAAAAAAAAAAAELmAvoSkhSOWiiKv44VbWj-MzHHp5n-oT9Wu7nFo-ZQ/img.png?credential=yqXZFxpELC7KVnFOS48ylbz2pIh7yKj8&expires=1777561199&allow_ip=&allow_referer=&signature=5wHsvgeLhki8Qahdy2oNdET63wc%3D)
이 글은 알고리즘을 설계할 때 많이 사용되는 대표적인 자료구조 중 하나인 스택(Stack)과 큐(Queue)에 대해 정리한 글입니다.
스택 (Stack)
스택의 개념
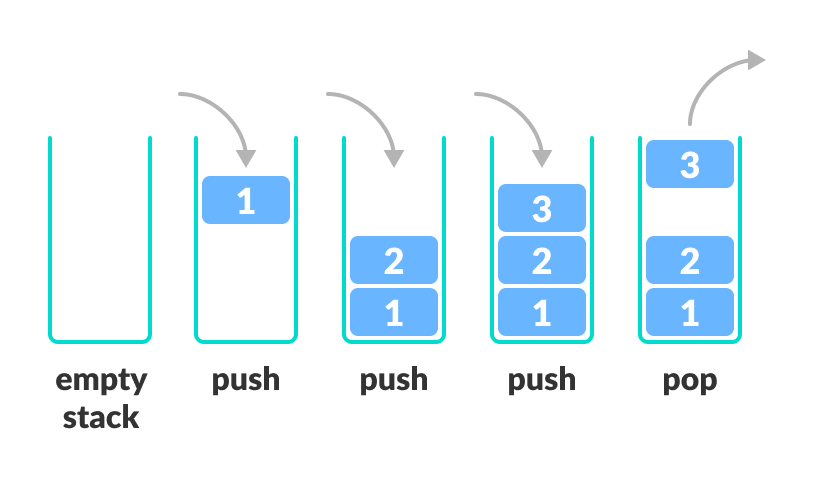
- 스택은 데이터를 임시 저장하는 데 사용하는 자료구조
- 후입선출, LIFO (Last-In, First-Out) : 가장 나중에 들어간 데이터가 가장 먼저 나오며, 물리적인 동작으로는 한쪽 끝에서만 데이터를 넣거나 뺼 수 있는 구조
스택의 주요 연산
스택의 기본 연산은 언어에 상관없이 동일하나, 구현 방법이나 문법은 언어 별로 차이가 있을 수 있다.
Push
- 새로운 데이터를 스택의 맨 위(top)에 삽입
- ex)
push(item)
Pop
- 스택의 맨 위에 있는 데이터를 제거하고 반환
- 스택이 비어 있는 상태에서
pop을 시도하면 에러(underflow)가 발생 - ex)
item = pop()
Peak (Top)
- 스택의 맨 위에 있는 데이터를 제거하지 않고 반환
- 스택이 비어 있는 경우, 접근이 불가능하기 때문에 주의가 필요
- ex)
item = peek()
IsEmpty / IsFull
- 스택이 비었는지(
isEmpty) 혹은 가득 차 있는지(isFull) 확인하는 유틸리티 함수 - 정적 배열로 구현 시
isFull을 체크하여 오버플로(overflow) 방지에 사용
C++ 표준 라이브러리(STL)의std::stack
✅push(): 요소를 스택에 추가 (ex.stack.push(item))
✅pop(): 스택의 맨 위 요소를 제거 (ex.stack.pop())
✅top(): 스택의 맨 위 요소 반환 (ex.item = stack.top())
✅empty(): 스택이 비어 있는지 확인 (ex.stack.empty())
✅size(): 스택의 크기(개수) 반환 (ex.stack.size())
스택의 구현 방식
스택은 크게 배열(Array) 혹은 연결 리스트(Linked-List) 방식으로 구현할 수 있다.
배열 기반 스택
- 구조
- 내부적으로 정적 혹은 동적 배열을 사용하여 데이터를 선형으로 저장
top인덱스를 별도로 관리하여 스택의 맨 위를 추적
- 장점
- 인덱스를 통한 접근이 가능하므로, 구현이 간단하고 직관적
- 각 연산의 시간 복잡도가 $ O(1) $ (단, 동적 배열 재할당 시 최악의 경우 $ O(n) $)
- 단점
- 정적 배열을 사용할 경우, 최대 크기를 미리 지정해야 하므로 오버플로(overflow)가 발생할 수 있음
- 동적 배열을 사용할 경우, 재할당 시점에서 복사가 필요할 수 있으며 이때 시간 복잡도는 $ O(n) $ 까지 증가할 수 있음
- 배열 기반 C++ 스타일의 가상 코드
class ArrayStack {
private:
int* stackArray;
int capacity; // 최대 크기
int top; // 맨 위를 가리키는 인덱스
public:
ArrayStack(int size) {
capacity = size;
stackArray = new int[capacity];
top = -1;
}
~ArrayStack() {
delete[] stackArray;
}
bool isEmpty() {
return (top == -1);
}
bool isFull() {
return (top == capacity - 1);
}
void push(int data) {
if (isFull()) {
throw std::overflow_error("Stack Overflow");
}
stackArray[++top] = data;
}
int pop() {
if (isEmpty()) {
throw std::underflow_error("Stack Underflow");
}
return stackArray[top--];
}
int peek() {
if (isEmpty()) {
throw std::underflow_error("Stack is Empty");
}
return stackArray[top];
}
};연결 리스트 기반 스택
- 구조
- 단일 연결 리스트(singly linked list)를 이용하여 스택을 구현할 수 있음
- 삽입 및 삭제는 주로 헤드 노드 쪽에서만 이루어짐
- 장점
- 크기가 동적으로 증가/감소하므로, 배열 기반 스택처럼 오버플로 문제거 거의 없음 (힙 메모리 제한이 허용되는 한)
push혹은pop연산 시 기존 노드를 옮길 필요가 없으므로, 삽입 및 삭제가 효율적
- 단점
- 각 노드가 별도의 메모리 공간에 존재하므로 포인터 관리가 필요하며, 오버헤드가 배열보다 크고 메모리 지역성이 떨어짐
- 구현이 배열 기반보다 조금 더 복잡
- 연결 리스트 기반 C++ 스타일의 가상 코드
struct Node {
int data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};
class LinkedStack {
private:
Node* head; // 스택의 top 역할
public:
LinkedStack() : head(nullptr) {}
~LinkedStack() {
while (!isEmpty()) {
pop();
}
}
bool isEmpty() {
return (head == nullptr);
}
void push(int value) {
Node* newNode = new Node(value);
newNode->next = head;
head = newNode;
}
int pop() {
if (isEmpty()) {
throw std::underflow_error("Stack Underflow");
}
Node* temp = head;
int poppedValue = temp->data;
head = head->next;
delete temp;
return poppedValue;
}
int peek() {
if (isEmpty()) {
throw std::underflow_error("Stack is Empty");
}
return head->data;
}
};스택의 시간 복잡도
push: 평균 $ O(1) $pop: 평균 $ O(1) $peek: 평균 $ O(1) $- 단, 동적 배열에서 재할당 시점에 한해 내부 복사가 발생할 수 있어 최악의 경우 $ O(n) $이 될수 있으나, 평균적으로 상수 시간에 가까운 성능이 나타남
스택 사용 시 주의 사항
- 오버플로(overflow) / 언더플로(underflow)
- 배열 기반 스택에서 최대 크기를 초과하여
push연산을 수행하면 오버플로 발생 - 배열 기반 스택이 비어 있는 상태에서
pop연산을 수행하면 언더플로가 발생
- 배열 기반 스택에서 최대 크기를 초과하여
- 포인터 및 메모리 관리
- 연결 리스트 기반 스택은 동적 메모리를 사용하므로, 노드 생성 및 삭제 시 메모리 누수가 발생하지 않도록 주의가 필요
- 성능 고려
- 크기가 많이 변동되는 상황에서는 동적 배열 혹은 연결 리스트 기반 스택을 선택하는 것이 좋음
- 데이터를 빠르게 인덱스로 접근해야 하는 경우, 연결 리스트보다는 배열 기반이 성능적으로 좋음 (단, 스택은 맨 위 외에는 접근하지 않는 자료구조)
- 언어별 구현
- C++ STL에는 스택을 추상화한
std::stack어댑터가 존재 (기본적으로 deque을 내부 컨테이너로 사용) - Java에는
Stack클래스가 존재하지만, 주로Deque(ex.ArrayDeque)을 스택으로 활용하는 방법이 권장
- C++ STL에는 스택을 추상화한
큐 (Queue)
큐의 개념

- 큐는 데이터를 임시 저장하는 데 사용되는 자료구조
- 선입선출, FIFO (First-In, First-Out) : 가장 먼저 들어온 데이터가 가장 먼저 나가는 구조
큐의 주요 연산
큐의 기본 연산은 언어에 상관없이 동일하나, 구현 방법이나 문법은 언어 별로 차이가 있을 수 있다.
Enqueue (Push, Offer)
- 큐의 뒤(rear) 위치에 새로운 데이터를 삽입
- ex)
enqueue(data)
Dequeue (Pop, Poll)
- 큐의 앞(front)에 있는 데이터를 제거하고 반환
- 큐가 비어 있는 상태에서
dequeue를 시도하면 언더플로(underflow)가 발생할 수 있음 - ex)
data = dequeue()
Peek (Front)
- 큐의 맨 앞에 있는 데이터를 제거하지 않고 반환
- ex)
data = front()
IsEmpty / IsFull
- 큐가 비었는지(
isEmpty) 혹은 가득 찼는지(isFull) 확인하는 유틸리티 함수 - 정적 배열로 구현 시
isFull체크를 통해 오버플로(overflow)를 방지하는 데 사용
C++ 표준 라이브러리(STL)의std::queue
✅push(): 요소를 큐 맨 뒤에 추가 (ex.queue.push(item))
✅pop(): 큐의 맨 앞 요소를 제거 (ex.queue.pop())
✅front(): 큐의 맨 앞 요소를 반환 (ex.item = queue.front())
✅empty(): 큐가 비어 있는지 확인 (ex.queue.empty())
✅size(): 큐의 크기(개수) 반환 (ex.queue.size())
큐의 구현 방식
스택은 크게 배열(Array) 혹은 연결 리스트(Linked-List) 방식으로 구현할 수 있다.
배열 기반 큐
- 구조
- 내부적으로 배열을 사용하여 선형 데이터 관리
- 일반적으로
front와rear인덱스를 유지하며, 큐의 맨 앞과 맨 뒤를 추적
- 문제점
- 단순히
front와rear를 증가시키기만 하면, 배열의 끝에 도달했을 때 더 이상 큐가 동작하지 않는 문제가 발생할 수 있음
- 단순히
- 해결책 : 원형 큐(Circular Queue)
- 배열의 양 끝이 연결된 것처럼 사용하며, 공간을 효율적으로 활용
rear인덱스가 배열의 마지막 인덱스에 도달하면 다시 0번 인덱스로 돌아가도록(모듈로 연산 활용) 구성
- 배열 기반 C++ 스타일의 가상 코드
class CircularQueue {
private:
int* queueArray;
int capacity;
int front;
int rear;
int count; // 큐 내 원소 수
public:
CircularQueue(int size) : capacity(size), front(0), rear(0), count(0) {
queueArray = new int[capacity];
}
~CircularQueue() {
delete[] queueArray;
}
bool isEmpty() {
return (count == 0);
}
bool isFull() {
return (count == capacity);
}
void enqueue(int data) {
if (isFull()) {
throw std::overflow_error("Queue Overflow");
}
queueArray[rear] = data;
rear = (rear + 1) % capacity;
count++;
}
int dequeue() {
if (isEmpty()) {
throw std::underflow_error("Queue Underflow");
}
int value = queueArray[front];
front = (front + 1) % capacity;
count--;
return value;
}
int frontElement() {
if (isEmpty()) {
throw std::underflow_error("Queue is Empty");
}
return queueArray[front];
}
int size() {
return count;
}
};연결 리스트 기반 큐
- 구조
- 연결 리스트를 이용하여 큐의 맨 앞과 뒤를 가리키는 포인터 두 개를 유지
- 새 노드를 삽입할 때는
rear포인터가 가리키는 위치 뒤에 노드를 추가하고,rear를 새 노드로 갱신 - 데이터를 제거할 때는
front포인터가 가리키는 노드를 제거하고,front를 다음 노드로 이동
- 장점
- 원소 개수에 따라 동적으로 크기가 늘어나고, 배열 기반 큐처럼 미리 크기를 정할 필요가 없음
- 오버플로 위험이 작으며, 원형 큐의 복잡한 인덱스 관리를 피할 수 있음
- 단점
- 노드 연결을 위한 포인터 관리가 필요하고, 각 노드마다 추가적인 메모리 사용(포인터 공간)이 발생
- 메모리 할당 및 해제가 자주 일어날 경우 성능 저하가 있을 수 있음
- 연결 리스트 기반 C++ 스타일의 가상 코드
struct Node {
int data;
Node* next;
Node(int value) : data(value), next(nullptr) {}
};
class LinkedQueue {
private:
Node* front;
Node* rear;
int count;
public:
LinkedQueue() : front(nullptr), rear(nullptr), count(0) {}
~LinkedQueue() {
while (!isEmpty()) {
dequeue();
}
}
bool isEmpty() {
return (count == 0);
}
void enqueue(int value) {
Node* newNode = new Node(value);
if (isEmpty()) {
front = newNode;
rear = newNode;
} else {
rear->next = newNode;
rear = newNode;
}
count++;
}
int dequeue() {
if (isEmpty()) {
throw std::underflow_error("Queue Underflow");
}
Node* temp = front;
int data = temp->data;
front = front->next;
delete temp;
count--;
if (isEmpty()) {
rear = nullptr; // 모든 노드를 제거했다면 rear도 nullptr
}
return data;
}
int frontElement() {
if (isEmpty()) {
throw std::underflow_error("Queue is Empty");
}
return front->data;
}
int size() {
return count;
}
};큐의 시간 복잡도
enqueue: 평균 $ O(1) $dequeue: 평균 $ O(1) $peek: 평균 $ O(1) $isEmpty/isFull: 평균 $ O(1) $- 배열 기반 구현에서는 재할당(동적 배열 사용 시) 등이 발생할 수 있으나, 원형 큐 형태로 구현하면 매 연산 시 $ O(1) $이 유지됨
큐 사용 시 주의 사항
- 오버플로(overflow) / 언더플로(underflow)
- 배열 기반 큐에서 크기를 초과하여
enqueue를 수행하면 오버플로(overflow) 발생 - 배열 기반 큐가 비어 있는 상태에서
dequeue를 수행하면 언더플로(underflow) 발생
- 배열 기반 큐에서 크기를 초과하여
- 메모리 관리
- 연결 리스트 기반 큐는 노드 동적 할당 및 해제가 많으므로, 메모리 누수나 성능 저하가 발생하지 않도록 주의가 필요
- 전역적으로 대규모 큐를 배치하면, 배열 기반 구현 시 메모리 사용량을 고려해야 함
- 사용 목적에 맞는 구현
- 고정된 크기(or 상한이 명확한)이고 빠른 인덱스 접근이 필요 없다면 배열 기반 원형 큐가 간단하고 효율적
- 크기가 유동적이고 예측하기 어려우며 빈번한 삽입 및 삭제가 이루어지면 연결 리스트 기반이 더 안전
- 언어별 구현
- C++ STL에서
std::queue는 큐 어댑터로, 내부 컨테이너로std::deque등을 사용 - Java에서는
Queue인터페이스(LinkedListorArrayDeque) 사용 - Python에서는
collections.deque를 사용
- C++ STL에서
'🧠 CS > 자료구조' 카테고리의 다른 글
| [자료구조] C++ Container Library : Sequential Containers - vector (0) | 2025.04.26 |
|---|---|
| [자료구조] 우선순위 큐(priority queue)의 정렬 안정성 (0) | 2025.04.06 |
| [자료구조] 서로소 집합 자료구조 (Disjoint Set Union, DSU) - Union Find (0) | 2025.03.03 |
| [자료구조] 정적 배열과 동적 배열 (Static Array & Dynamic Array) (0) | 2025.02.12 |
| [자료구조] 배열(Array)과 DAT(Direct Access Table) (0) | 2025.01.27 |