![[알고리즘] 최단 경로 알고리즘 - 플러드 필(Flood Fill)과 다익스트라(Dijkstra)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbtHMjn%2FbtsMzhODmyr%2FSG2MHKx7ZIZAnkf61Df070%2Fimg.png)

[알고리즘] 최단 경로 알고리즘 - 플러드 필(Flood Fill)과 다익스트라(Dijkstra)🧠 CS/알고리즘2025. 3. 2. 01:02
Table of Contents
이 글은 BFS 알고리즘을 활용하여 최단 경로를 탐색하는 플러드 필(Flood Fill)과 다익스트라(Dijkstra) 알고리즘에 대해 정리한 글입니다.
플러드 필 (Flood Fill)
플러드 필의 개념
정의
- 플러드 필은 시작 지점에서부터 같은 값(색, 타입 등)을 가지며 연결되어 있는 모든 칸을 탐색(방문)하고, 그 칸들에 대해 특정 작업(색, 값 갱신, 카운트 등)을 수행하는 알고리즘
연결 기준
- 2D 격자에서 일반적으로 상, 하, 좌, 우의 4방향(4-connected)을 인접한 영역으로 취급
- 문제에 따라서, 대각선 4방향을 포함하여 8방향(8-connected)을 인접한 영역으로 취급하기도 함
주요 특징
- 탐색은 같은 값, 혹은 특정 조건을 만족하는 값을 대상으로 수행
- 탐색된 영역에 대해 일괄적으로 처리
- 방문 체크(
visited배열, 혹은 값 변경 등)를 반드시 수행하여야 중복 방문이 발생하지 않음
구현 알고리즘
- 깊이 우선 탐색(DFS) 혹은 너비 우선 탐색(BFS)을 사용하여 시작 지점과 연결된 모든 칸을 탐색 (이번 글에서는 BFS를 사용하여 탐색하는 방법에 대해 소개한다.)
플러드 필의 기본 흐름

- 시작점 지정
- 격자
grid의(row, col)좌표에서 알고리즘 시작
- 격자
- 탐색 조건 설정
- 인접한 영역(4 방향, 8 방향 등) 조건 설정
- 인접한 영역의 값이 같으면 계속 진행
- 인접한 영역이 범위를 벗어나거나, 값이 다르면 중지
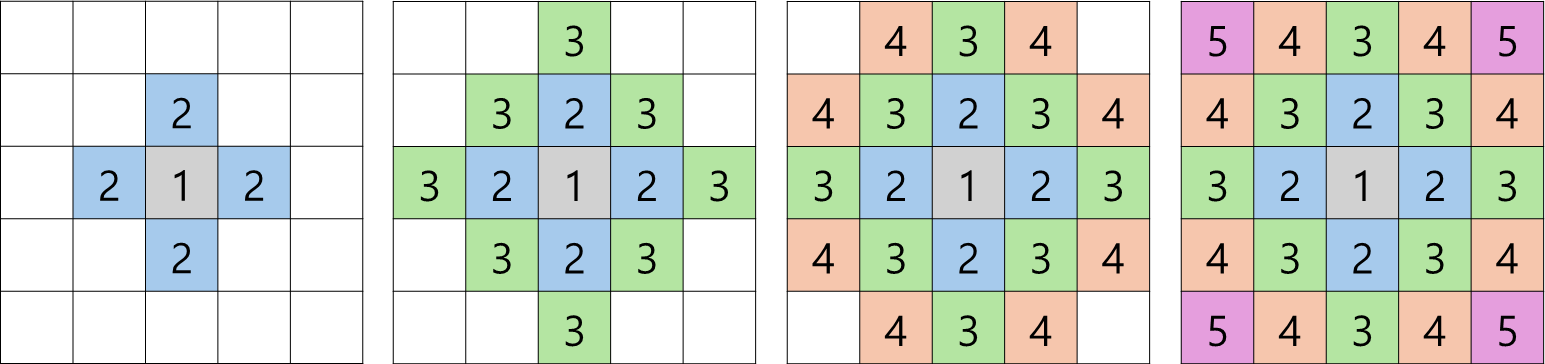
- 탐색 실행 (BFS 실행)
- 방향 배열을 이용하여 인접한 영역에 대해 탐색 수행
- 결과
- 탐색 조건에 해당하는 영역의 모든 칸에 방문 플래그가 세팅
플러드 필의 구현
플러드 필 기본 구현
기본적으로 플러드 필은 BFS 알고리즘을 사용하며, visited 배열의 경우 2차원 배열로 처리한다. (visited 배열의 크기와 문제에서 주어지는 map의 크기는 동일)
- 대기열 준비 (
queue자료구조와(y, x)좌표를 처리할 구조체 사용) - 입력으로 받은 시작 노드(시작 좌표)를
queue에 등록 - 맨 앞 노드 확인 및 추출 (
now노드) - 현재 노드(
now노드)를 기준으로 상하좌우를 탐색하여next노드 찾기 next노드를queue에 등록queue가 비기 전까지 3 ~ 5번 반복
위 구현 방법을 코드(C++)로 구현하면 아래와 같다.
#include <iostream>
#include <queue>
using namespace std;
int visited[7][7]; // index : (y, x) & value : 방문여부
// 방향 배열 (ex. 상 하 좌 우)
int ydir[] = {-1, 1, 0, 0};
int xdir[] = {0, 0, -1, 1};
// 맵 상에서의 노드 정보
struct Node {
int y;
int x;
};
void bfs(int y, int x) {
// 1. 대기열 준비
queue<Node> que;
// 2. 시작 노드 큐에 등록
que.push({y, x});
visited[y][x] = 1; // 방문 기록
// 3 ~ 5번 반복(큐가 비기 전까지)
while (!que.empty()) {
// 3. 맨 앞 노드 확인 및 추출
Node now = que.front();
que.pop();
// 4. now 노드 기준 next 노드 찾기 (방향 배열 사용)
for (int i = 0; i < 4; i++) {
int ny = now.y + ydir[i];
int nx = now.x + xdir[i];
if (ny >= 7 || nx >= 7 || ny < 0 || nx < 0) continue; // 맵 범위 체크
if (visited[ny][nx] != 0) continue; // 방문 여부 체크
// 5. next 등록
visited[ny][nx] = 1;
que.push({ny, nx});
}
}
}
int main() {
// ex. visited 배열 시작 노드 좌표 기준 (3, 3)
// ex. visited 배열 범위 내에서 플러드 필 진행
bfs(3, 3);
for (int i = 0; i < 7; i++) {
for (int j = 0; j < 7; j++) {
cout << visited[i][j] << " ";
}
cout << "\n";
}
return 0;
}플러드 필 활용 구현
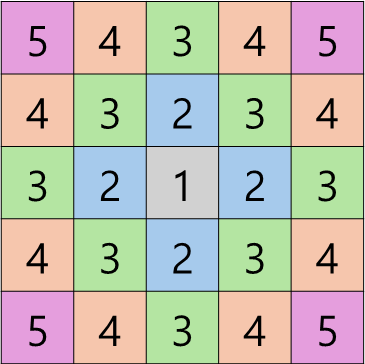
플러드 필에서 방문 여부를 확인하는 visited 배열을 활용하면 시작 노드에서 특정 노드까지의 거리를 알 수 있다.
- 전체적인 구현 순서는 기본 구현과 동일하며, 다음 노드를
queue에 등록하며 방문 처리할 때1(혹은true)이 아닌visited[now.y][now.x] + 1로 처리
#include <iostream>
#include <queue>
using namespace std;
int visited[7][7]; // index : (y, x) & value : 방문여부
// 방향 배열 (ex. 상 하 좌 우)
int ydir[] = {-1, 1, 0, 0};
int xdir[] = {0, 0, -1, 1};
// 맵 상에서의 노드 정보
struct Node {
int y;
int x;
};
void bfs(int y, int x) {
// 1. 대기열 준비
queue<Node> que;
// 2. 시작 노드 큐에 등록
que.push({y, x});
visited[y][x] = 1; // 방문 기록
// 3 ~ 5번 반복(큐가 비기 전까지)
while (!que.empty()) {
// 3. 맨 앞 노드 확인 및 추출
Node now = que.front();
que.pop();
// 4. now 노드 기준 next 노드 찾기 (방향 배열 사용)
for (int i = 0; i < 4; i++) {
int ny = now.y + ydir[i];
int nx = now.x + xdir[i];
if (ny >= 7 || nx >= 7 || ny < 0 || nx < 0) continue; // 맵 범위 체크
if (visited[ny][nx] != 0) continue; // 방문 여부 체크
// 5. next 등록
visited[ny][nx] = visited[now.y][now.x] + 1;
que.push({ny, nx});
}
}
}
int main() {
// ex. visited 배열 시작 노드 좌표 기준 (3, 3)
// ex. visited 배열 범위 내에서 플러드 필 진행
bfs(3, 3);
for (int i = 0; i < 7; i++) {
for (int j = 0; j < 7; j++) {
cout << visited[i][j] << " ";
}
cout << "\n";
}
return 0;
}플러드 필 구현 시 주의사항
- 방문 체크
- 이미 방문한 칸은 다시 탐색하지 않도록 처리
- 방문 처리 배열(
visited)을 따로 사용하거나map의 값을 다른 값으로 바꿔서 구분 가능 (일반적으로 방문 처리 배열을 따로 사용하는 편이 좋다.)
- 시작점의 값과 동일한 값의 칸만 탐색
- 조건을 "같은 값이면 계속"으로 잡지 않으면 다른 영역까지 침범할 가능성이 있음
플러드 필 알고리즘의 복잡도와 성능
시간 복잡도
- 격자의 크기를 $ N \times M $이라고 할 때, 최악의 경우는 모든 칸을 한 번씩 방문할 수 있음 ( $ O(N \times M) $ )
- 일반적으로 정해진 영역만을 체크하므로, 탐색하는 영역의 크기에 비례
공간 복잡도
- 최악의 경우
queue가 $ O(N \times M) $의 원소를 가질 수 있음 (BFS의 경우) - 방문을 처리할 보조 배열을 사용하는 경우 공간 복잡도가 증가할 수 있음
성능 최적화
- 일반적으로 $ O(N \times M) $안에서 충분히 해결 가능한 문제면, 별 다른 최적화 없이도 괜찮은 편
알고리즘 문제 예시
플러드 필 알고리즘은 BFS 알고리즘의 종류 중 하나로, 백준과 같은 사이트의 알고리즘 분류 상 BFS로 되어 있다.
특정 위치까지의 최단 거리 구하기
✔️ 2178번: 미로 탐색
모든 좌표에 대한 최단 거리 구하기
✔️ 7576번: 토마토
영역 확인 (영역 개수 체크)
다익스트라 (Dijkstra)
다익스트라의 개념
정의
- 음이 아닌 가중치(거리, 비용 등)를 가진 유향 혹은 무향 그래프에서, 한 정점에서 다른 모든 정점까지의 최단 거리를 구하는 알고리즘
- "지금까지 발견된 최소 비용을 바탕으로 가장 유망한(비용이 가장 작은) 정점을 먼저 선택해 확장한다"는 그리디(Greedy) 원리가 핵심 아이디어
기본 아이디어
- 가장 가까운(거리 혹은 비용이 가장 작은) 정점을 먼저 확정
- 시작점에서 각 정점까지의 거리를 저장하는 배열(ex.
dist[v])을 두고, 아직 방문되지 않은 정점 중 가장 거리(비용)가 작은 정점을 선택해 그 거리(비용)를 확정 - 그 정점을 통해 이동할 수 있는 인접 정점들의 거리(비용) 값을 갱신
- 시작점에서 각 정점까지의 거리를 저장하는 배열(ex.
- 그리디(Greedy) 접근
- 매 단계에서 가장 작은 거리(비용) 값을 가진 정점을 선택하면, 그 정점에 대한 최단 거리가 확정된 것이라고 할 수 있음 (음수 가중치가 없기 때문에 가능)
- 우선순위 큐(Priority Queue) 활용
- 단순 구현 시, 매번 "방문하지 않은 정점 중 거리(비용) 값이 최소인 정잠"을 선형 검색하면 $ O(V^2) $ 시간이 걸릴 수 있음
- 최적 구현에서는 우선순위 큐(최소 힙)를 사용해, 가장 작은 거리(비용) 값을 가진 정점을 빠르게 꺼내어 처리하면 일반적으로 $ O(E \log V) $ 시간이 걸릴 수 있음
주요 자료구조
- 인접 리스트
map[u]에(v, w)형태로 저장 : 정점u에서v로 가는 간선, 가중치w- 인접 리스트를 사용하면 간선 수가 많지 않은 희소 그래프에서도 효율적으로 동작
- 거리 배열
dist[v]: 시작 노드에서v까지의 최단 거리 (초기값 =INT_MAX, 시작 노드 =0)
- 우선순위 큐 (최소 힙)
- 항상 현재까지 가장 거리(비용)가 작은 정점을 빠르게 꺼내 처리
다익스트라의 기본 흐름
- 초기화
dist[start] = 0(시작 정점까지의 거리는 0)- 나머지 정점
node에 대해서dist[node] = INT_MAX(아직 거리를 모름) - 우선순위 큐에 시작 정점의 (노드, 거리)
(start, 0)쌍을 추가
- 우선순위 큐 반복
- 우선순위 큐에서 가장 작은 거리를 가진 (노드, 거리) 쌍을 꺼냄 (
now = pque.front()/ 단,now = {node,dist}) dist[now.node] < now.dist라면, 무시- 그렇지 않다면,
now.node의 모든 인접 간선을 확인 (next = map[now.node][idx]/ 단,next = {node, dist})dist[next.node] > dist[now.node] + next.dist를 만족하면,dist[next.node] = dist[now.node] + next.dist로 갱신하고, 우선순위 큐에(next.node, dist[now.node] + next.dist)추가
- 우선순위 큐에서 가장 작은 거리를 가진 (노드, 거리) 쌍을 꺼냄 (
- 반복 종료
- 우선순위 큐가 빌 때까지 반복 (또는 모든 노드가 확정되었다고 판단 시 종료)
- 알고리즘이 종료되면
dist[v]는 시작점에서부터v까지의 최단 거리
다익스트라의 구현
- 대기열 준비 (우선순위 큐 준비)
- 시작 노드를
priority_queue에 등록 (pque.push({start, 0}) priority_queue의 최상위 노드 선택 (now = pque.top())- 현재 노드에서 다음 노드로 연결된 모든 간선 체크
priority_queue에 다음 노드 등록 (pque.push{next.node, nextcost})
#include <iostream>
#include <queue>
#include <vector>
#include <climits>
using namespace std;
struct Edge {
int node; // 연결되는 노드 (to)
int cost; // 가중치
bool operator<(Edge right)const {
// weight가 가장 저렴한 간선을 우선적으로 뽑는다.
if (cost < right.cost) return false; // 가중치가 높은 거 우선 left < right
if (cost > right.cost) return true;
return false;
}
};
int N, M; // N: 노드 개수 // M: 간선 정보
vector<Edge> vect[20]; // 실제 간선 정보
int dist[20];
void dijkstra(int start) {
// 1. priority_queue 준비
priority_queue<Edge> pque; // 간선 정보 > Dijkstra 탐색 용도
// +a 정답 배열 준비 (초기값 = MAX)
for (int i = 0; i < N; i++) {
dist[i] = INT_MAX;
}
// 2. 시작 노드를 queue에 등록
pque.push({start, 0});
dist[start] = 0;
// Dijkstra 구현 단계
while (!pque.empty()) {
// 3. priority_queue 최상위 노드(cost가 가장 저렴한 간선) 선택
Edge now = pque.top(); // now 확정 = 앞으로 더 저렴하게 갈 수 있는 방법은 없다.
pque.pop();
if (dist[now.node] < now.cost) continue; // 예외처리로 더미 제거 필수!! (안하면 더미가 넘쳐남...)
// 4. now -> next 간선 찾기
for (int i = 0; i < vect[now.node].size(); i++) {
Edge next = vect[now.node][i]; // next 후보 확인
int nextcost = dist[now.node] + next.cost; // 누적합 계산 (now까지의 비용 + next 가중치)
if (nextcost >= dist[next.node]) continue;
dist[next.node] = nextcost; // 정답 배열에 기록
// 5. priority_queue에 next 등록
pque.push({ next.node, nextcost });
}
}
for (int i = 1; i < N; i++) {
cout << i << "까지의 거리 : " << dist[i] << "\n";
}
}
int main() {
cin >> N >> M;
for (int i = 0; i < M; i++) {
int from, to, cost;
cin >> from >> to >> cost;
// 양방향 연결
vect[from].push_back({ to, cost });
vect[to].push_back({ from, cost });
}
// 시작 노드 = 0
dijkstra(0);
}다익스트라 알고리즘의 시간 복잡도
선형 검색(우선순위 큐 없는) 버전
- 방문하지 않은 모든 정점 중
dist[v]가 가장 작은 정점을 매번 찾으려면 $ O(V) $ 탐색 필요 - 모든 정점을 처리하기 때문에 $ O(V^2) $ 필요
- 간선이 매우 많지 않은(희소 그래프) 환경에서는 우선순위 큐 방식이 훨씬 빠르게 동작
우선순위 큐(최소 힙) 버전
- 그래프가 인접 리스트로 주어졌을 때, 각 정점에 우선순위 큐에 최대 여러 번 들어갈 수 있음 (갱신될 때마다)
- 일반적으로 간선 수
E만큼 갱신이 일어날 수 있으므로, 우선순위 큐 연산(push/pop)이 $ O(\log V) $ 씩 걸려 전체적으로 $ O(E \log V) $ 필요
다익스트라의 주의사항
- 음수 간선
- 다익스트라는 음수 가중치가 존재하면 올바른 해를 보장할 수 없음
- 음수 간선이 있는 경우, 벨만-포드나 플로이드-위셜 등의 다른 알고리즘을 사용해야 함
- 메모리 사용
- 인접 리스트, 우선순위 큐 등에 대한 메모리 제한 고려 필요
- 일반적으로 간선이 많아도 $ O(E \log V) $ 시간 및 공간 내에서 처리 가능
- 중복 노드 삽입
- 한 노드가 거리(비용)가 생긴될 때마다 우선순위 큐에 들어가므로, 우선순위 큐에서 같은 노드가 여러 번 나올 수 있음
- 이를 처리하기 위해 꺼낸 노드가 현재 거리와 다르면 무시하는 조건이 필요 (
if (dist[node] < now.cost) continue;)
- DAG(방향성 비순환 그래프)인 경우
- DAG에서 최단 경로는 위상 정렬 기반 DP로 더 빠르게 구할 수 있음
- 일반 그래프에서는 다익스트라가 범용적으로 사용됨
최단 경로 알고리즘 비교
BFS
- 모든 간선의 가중치가 동일(특히 1)하거나 가중치가 없는 그래프인 경우 사용
- 거리(간선 수)가 가장 적은 경로를 찾을 수 있음
- 구현이 간단 (
queue사용)
다익스트라 (Dijkstra)
- 간선 가중치가 양의 실수(0 이상)인 그래프인 경우 사용
- 가장 널리 사용되는 최단 경로 알고리즘으로, 우선순위 큐를 사용하면 $ O(E \log V) $로 빠름
벨만-포드 (Bellman-Ford)
- 음수 가중치가 있는 그래프인 경우 사용하며, 음수 사이클 판별이 가능
- $ O(V \times E) $의 시간복잡도를 가지므로 다익스트라에 비해 느림
- 음수 사이클이 존재하면 무한히 비용을 줄일 수 있으므로, 이를 판별하여 경로가 없음을 알릴 수 있음
V가 크면 비효율적이지만,E가 아주 작거나 음수 간선 처리가 필요한 특정 상황에서 사용
플로이드-워셜 (Floyd-Warshall)
- 모든 정점 쌍 사이의 최단 경로를 한꺼번에 구해야 하는 상황에서 사용
- 3중 루프를 사용하기 떄문에 $ O(V^3) $의 시간이 소요되며, 음수 간선 및 음수 사이클 모두 판별이 가능
V의 규모가 작은 경우(수십 ~ 수백) 사용하며, 모든 쌍의 최단 거리 문제가 자주 나타나는 상황에서 사용
'🧠 CS > 알고리즘' 카테고리의 다른 글
| [알고리즘] 다익스트라 알고리즘에서 최단 경로 기록 (0) | 2025.04.06 |
|---|---|
| [알고리즘] 최소 신장 트리(MST) - 크루스칼 알고리즘과 프림 알고리즘 (0) | 2025.03.03 |
| [알고리즘] 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS) (0) | 2025.02.26 |
| [알고리즘] 재귀(Recursion)와 백트래킹(Backtracking) (0) | 2025.02.25 |
| [알고리즘] 탐색 알고리즘 기본 (선형 탐색, 이진 탐색, 해시 탐색) (0) | 2025.02.16 |
@청월누리 :: DevKuk 개발 블로그
since 2025.01.27. ~ 개발자를 향해....🔥
![[알고리즘] 다익스트라 알고리즘에서 최단 경로 기록](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FesWnWj%2FbtsNac0GYL6%2FDTzKB18HrhwPHNGGaFSV3K%2Fimg.png)
![[알고리즘] 최소 신장 트리(MST) - 크루스칼 알고리즘과 프림 알고리즘](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FHhAGK%2FbtsMA7YMays%2FGU6q349T07CstDpSZNk5U0%2Fimg.png)
![[알고리즘] 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb5MflM%2FbtsMvNArD07%2FIYXI8fP4A5kESscBoG7qwK%2Fimg.png)
![[알고리즘] 재귀(Recursion)와 백트래킹(Backtracking)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb9QVIP%2FbtsMuu8vJit%2FVwHIM8E7KFqPqdfbgKUyiK%2Fimg.png)