![[자료구조] C++ Container Library : Associative Containers - set & map](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbEz3Cv%2FbtsNJSHxVav%2FPYC6q8cG37jiy6fds2PWP0%2Fimg.png)

[자료구조] C++ Container Library : Associative Containers - set & map🧠 CS/자료구조2025. 5. 5. 17:29
Table of Contents
C++ 표준 라이브러리(STL)의 일부인 컨테이너 라이브러리 중 연관 컨테이너(Associative Containers) 자료구조 중 std::set과 std::map에 대해 정리한 글입니다.
📚 연관 컨테이너 (Associative Containers)
📖 연관 컨테이너란?
- 키(
key)를 기반으로 데이터를 저장하고 빠르게 검색하도록 설계된 자료구조 - 데이터를 키(
key) 기준으로 정렬된 상태로 유지 - 내부적으로 이진 탐색 트리(Binary Search Tree)로 이루어져 있으며, C++ STL에서는 자가 균형 이진 탐색 트리(Self-Balancing Binary Search Tree, Red-Black Tree)로 이루어져 있음
📌 대표 컨테이너
👉 C++ STL에서 제공하는 4가지 기본 연관 컨테이너
set: 값만 저장하며, 중복 불가 |key만 존재하며, 자동 정렬multiset: 값만 저장하며, 중복 허용 |key만 존재하고, 자동 정렬map: 키 - 값 쌍으로 저장하며 중복 불가 |key - value의 형태이며, 자동 정렬multimap: 키 - 값 쌍으로 저장하며 중복 허용 |key - value의 형태이며, 자동 정렬
📖 내부 동작 방식
- 내부적으로 이진 탐색 트리(BST) 구조를 기반으로 동작 ➡️ 삽입, 삭제, 탐색 모두 $ O(\log N) $
- 키(
key) 기준으로 자동 정렬되어,std::set과std::map등 모두 순회 시 정렬된 순서로 접근 가능
📌 연관 컨테이너는 언제 사용할까
- 키(
key)를 기준으로 빠르게 데이터를 검색하거나 관리할 때 (ex. 사전, 전화번호부) - 데이터가 항상 정렬된 상태로 필요한 경우 (ex. 고유 ID 목록)
- 빈번한 삽입, 삭제, 탐색이 필요한 경우 (ex. 데이터베이스 인덱스)
📚 std::set
📖 std::set
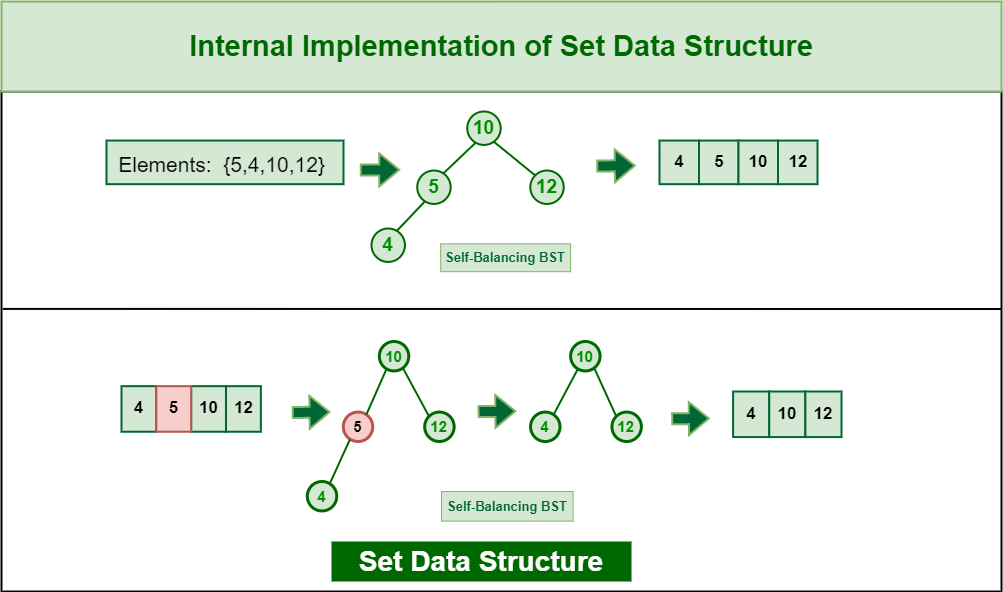
👉 중복되지 않는 값(키)를 자동으로 정렬된 상태로 저장하는 (연관) 컨테이너
- 값들은 자동으로 정렬
- 값은 모두 고유(Unique) 해야 함 ➡️ 중복을 허용하지 않음
- 값을 추가하면 자동으로 정렬된 위치에 삽입
- 내부적으로 이진 탐색 트리(BST)를 사용
📌 std::set 사용 예시 코드
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> s; // Declaring set
// Inserting elements
s.insert(10);
s.insert(5);
s.insert(12);
s.insert(4);
// Printing elements
for (const auto& i : s) {
cout << i << ' ';
}
cout << endl;
// Check if 10 is present
if (s.count(10)) {
cout << "Element 10 is present in the set" << endl;
}
// Erasing 5 from the set
s.erase(5);
// Printing elements after erasure
for (const auto& i : s) {
cout << i << ' ';
}
cout << endl;
// Printing minimum and maximum elements
cout << "Minimum element: " << *s.begin() << endl;
cout << "Maximum element: " << *prev(s.end()) << endl;
// Printing size of the set
cout << "Size of the set: " << s.size() << endl;
return 0;
}📖 std::set 핵심 특징
- 중복된 값을 허용하지 않음 ➡️ 중복된 값이 이미 존재하는 경우, 해당 값이 무시됨
- 기본적으로 오름차순으로 자동 정렬
- 탐색, 삽입, 삭제 시 $ O(\log N) $ 의 시간 복잡도를 가짐
- 내부적으로 자가 균형 이진 탐색 트리(보통 Red-Black Tree)로 구현
- 임의 접근(ex.
s[2]) 불가능 ➡️ iterator를 사용한 탐색만 가능
set은 왜 임의 접근(random access)이 불가능할까?
set은 내부적으로 이진 탐색 트리 구조를 가지고 있기 때문에 인덱스 개념이 존재하지 않아 임의 접근이 불가능하다. 대신 iterator를 사용한 순차 접근만 가능하다. $ O(\log N) $ 탐색은find()함수로 가능하고, 순차적 접근은iterator로 가능하다.
iterator란?
컨테이너의 원소를 가리키는 포인터와 비슷한 객체 ➡️ 단순 반복을 위한 인자가 아니라 컨테이너 안의 원소를 가리키고 이동할 수 있는 객체
✅ vector의 경우 iterator는 실제로 포인터와 거의 동일하게 동작
✅ list, set, map은 구조가 다르기 때문에 포인터는 사용할 수 없고 iterator만 사용
📖 set 주요 함수
insert(val): 값(val) 삽입 ➡️ 중복 시 무시 (이미 값이 set에 존재하는 경우 무시)find(val): 값 탐색 ➡️ iterator 반환 (값이 존재하지 않으면end()반환)erase(val): 해당 값(val)을 삭제erase(iterator): 해당 iterator 위치의 원소 삭제erase(first, last): iterator 범위([first, last)) 삭제
count(val): 값(val) 존재 여부 ➡️ 존재하면 1, 존재하지 않으면 0 반환clear(): 모든 값 삭제size(): 현재 저장되어 있는 원소 개수 반환begin(),end(): 시작 및 끝 iterator 반환begin(): (기본 정렬 상태에서) 가장 작은 원소를 가리키는 iteratorend(): 마지막 원소 다음을 가리키는 특수 iterator (마지막 원소를 가리키는 것 아님 주의!)
📌 iterator 기반 탐색 및 삭제
...
auto it = s.find(5);
if (it != s.end()) {
s.erase(it); // 해당 위치 원소 삭제
}
..find()함수는 해당 값의 iterator를 반환erase()함수는 iterator를 받아 삭제
📖 정렬 기준
📌 기본 정렬 기준
👉 std::set은 기본적으로 오름차순으로 자동 정렬
#include <iostream>
#include <set>
using namespace std;
set<int> s; // 오름차순 정렬📌 내림차순 정렬
#include <functional>
#include <iostream>
#include <set>
using namespace std;
set<int, greater<int>> s; // 내림차순 정렬📌 사용자 정의 정렬
👉 사용자가 임의로 정의한 기준에 맞춰 정렬 가능 (구조체, 함수 모두 가능)
✅ 사용자 구조체 정렬 기준 지정
#include <iostream>
#include <set>
#include <string>
struct Person {
std::string name;
int age;
bool operator<(const Person& other) const { return age < other.age; }
};
int main() {
std::set<Person> people;
people.insert({"Alice", 30});
people.insert({"Bob", 25});
people.insert({"Charlie", 40});
for (const auto& p : people) {
std::cout << p.name << " (" << p.age << ")\n";
}
return 0;
}✅ 사용자 정의 비교 함수 객체로 정렬
#include <iostream>
#include <set>
#include <string>
struct Person {
std::string name;
int age;
};
struct PersonCompare {
bool operator()(const Person& a, const Person& b) const {
return a.age < b.age;
}
};
int main() {
std::set<Person, PersonCompare> people;
people.insert({"Alice", 30});
people.insert({"Bob", 25});
people.insert({"Charlie", 40});
for (const auto& p : people) {
std::cout << p.name << " (" << p.age << ")\n";
}
return 0;
}📖 set 사용 예시
- 중복 없이 저장해야 할 때
- 항상 정렬된 상태가 필요할 때
- 자주 탐색(
find(),count())할 때
➡️ ex. 집합 연산 (교집합, 합집합 등) | 숫자 및 문자 중복 체크 | 입력값 중복 제거 후 정렬 상태 유지
📚 std::map
📖 std::map
👉 key-value 형태로 데이터를 저장하는 (연관) 컨테이너
key는 중복을 허용하지 않음 (항상 유일)- 항상 정렬된 상태를 유지 ➡️
key를 기준으로 정렬 - 내부적으로는 이진 탐색 트리(보통 Red-Black Tree) 사용
- 탐색, 삽입, 삭제 시 $ O(\log N) $ 의 시간 복잡도를 가짐
📌 std::map 사용 예시 코드
#include <iostream>
#include <map>
#include <string>
int main() {
std::map<std::string, int> score;
// Inserting elements
score["Alice"] = 95;
score["Bob"] = 88;
score["Charlie"] = 77;
// Printing elements
for (const auto& [name, sc] : score) {
std::cout << name << ": " << sc << '\n';
}
return 0;
}📖 std::map 핵심 특징
key-value쌍으로 저장되는 구조를 가짐key를 기준으로 자동으로 오름차순으로 정렬- 중복 키는 허용하지 않음
- 내부적으로 자가 균형 이진 트리(보통 Red-Black Tree)로 구현
- 삽입, 탐색, 삭제 시 $ O(\log N) $ 의 시간 복잡도
- 임의 접근(random access) 불가 ➡️ iterator를 사용한 접근
📖 map의 주요 함수
insert({key, value}): 새로운key-value삽입 ➡️ 중복 키 무시operator[]:key에 대응되는value접근 ➡️ 없으면 자동 생성at(key):key에 해당하는value접근 ➡️ 없으면 예외(std::out_of_range) 발생find(key):key에 해당하는 iterator 반환 ➡️ key가 없으면end()반환erase(key): 해당key-value쌍 제거count(key):key존재 여부 반환 ➡️key가 존재하면 1, 존재하지 않으면 0 반환begin(),end(): 시작 및 끝 iterator 반환begin(): 컨테이너의 첫 번째 원소를 가리키는 iterator 반환end(): 컨테이너의 마지막 원소 다음 위치를 가리키는 iterator 반환
[]vsat()차이
✅operator[key]:key가 존재하지 않으면 새롭게key-value를 생성
✅at(key):key가 존재하지 않으면 예외 발생 (std::out_of_range)
📌 iterator 기반 탐색
...
auto it = score.find("Bob");
if (it != score.end()) {
cout << it->first << " : " << it->second << endl;
}
...- iterator는
std::pair<const key, value>타입it->first:keyit->second:value
📖 정렬 기준
📌 기본 정렬 기준
👉 std::map은 기본적으로 key를 기준으로 오름차순으로 정렬
#include <iostream>
#include <map>
using namespace std;
map<int, string> m;📌 내림차순 정렬
#include <functional> // std::greater
#include <iostream>
#include <map>
using namespace std;
map<int, string, greater<int>> m;📌 사용자 정의 기준 정렬
✅ 구조체 operator< 오버로딩
#include <iostream>
#include <map>
using namespace std;
struct Person {
string name;
int age;
// 나이 기준으로 정렬
bool operator<(const Person& other) const { return age < other.age; }
};
map<Person, string> people;- 간단하고 일반적인 객체 정렬에서 자주 사용
operator<만 정의하면 기본 정렬 기준으로 사용
✅ 함수 객체 직접 넘기기
#include <iostream>
#include <map>
using namespace std;
struct CompareByLength {
bool operator()(const string& a, const string& b) const {
return a.length() < b.length(); // 길이 기준 정렬
}
};
map<string, int, CompareByLength> m;- 정렬 기준을
string의 길이로 바꾸고 싶을 유용 - 훨씬 유연하고 복잡한 비교가 가능
📖 map 사용 예시
- 키-값 쌍으로 데이터 관리 (예: 이름-점수, ID-정보)
- 정렬된 키로 순회 필요 시 (예: 사전순 이름 목록)
- 빈번한 키 기반 탐색 (
find(),at()) 필요 시
'🧠 CS > 자료구조' 카테고리의 다른 글
| [자료구조] 세그먼트 트리 (Segment Tree) 기본 개념 정리 (with. C++) (0) | 2025.06.22 |
|---|---|
| [자료구조] C++ Container Library : Associative Containers - multiset & multimap (0) | 2025.05.06 |
| [자료구조] C++ Container Library : Sequential Containers - list (0) | 2025.04.27 |
| [자료구조] C++ Container Library : Sequential Containers - deque (0) | 2025.04.27 |
| [자료구조] C++ Container Library : Sequential Containers - vector (0) | 2025.04.26 |
@청월누리 :: DevKuk 개발 블로그
since 2025.01.27. ~ 개발자를 향해....🔥
![[자료구조] 세그먼트 트리 (Segment Tree) 기본 개념 정리 (with. C++)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbziQ2t%2FbtsOLvKNEII%2FWDKOLw1yp12OsF3KseB3M1%2Fimg.png)
![[자료구조] C++ Container Library : Associative Containers - multiset & multimap](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FNolYt%2FbtsNLqJ27EZ%2FUFAoATwW4syuGTD119bg01%2Fimg.png)
![[자료구조] C++ Container Library : Sequential Containers - list](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbeSU7W%2FbtsNCg1j9qp%2FhMvpylH3KPXVowlquGFM60%2Fimg.png)
![[자료구조] C++ Container Library : Sequential Containers - deque](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbaL6Mv%2FbtsNAgPiIvD%2FMOVpWz7mbdFZEg3ZGWHQQ1%2Fimg.png)